
深層学習を用いた自然言語処理
概要
自然言語処理分野では、人がルールや辞書を作成し、テキスト情報を処理するルール型のシステムに代わって、機械学習や統計的手法を用いるシステムが注目されています。ルール型のシステムでは、時代の変化に対応するのが困難であること、ルールや辞書を作成する人的コストが高いことや、単語の細かなニュアンスを表現できないという問題点があり、システムの構築、維持が困難です。このページでは、機械学習のなかでも深層学習(Deep Learning)を用いた手法について説明します。
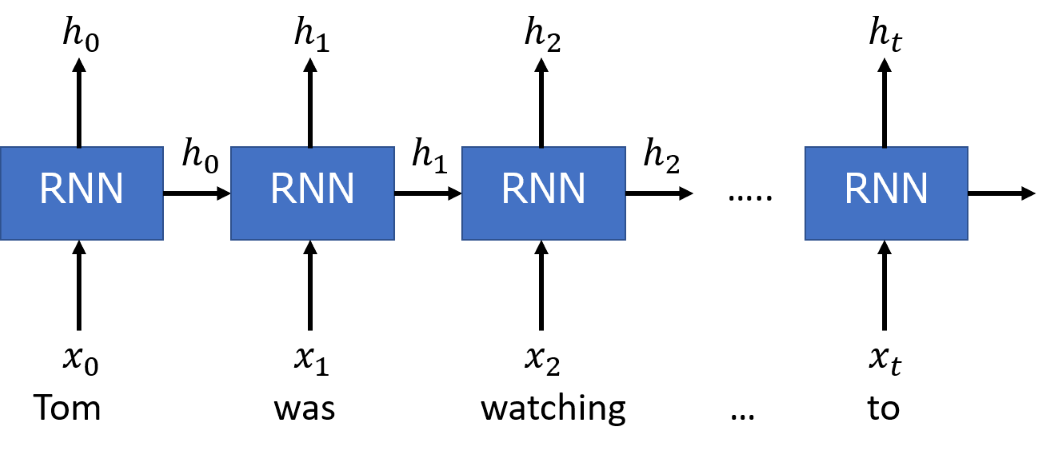
Recurrent Neural Network
自然言語処理分野で使われる深層学習(Deep Learning)の1つとして挙げられるのが、Recurrent Neural Network(RNN)です。RNNの特徴は、閉じた経路を持つ点です。この経路によって、過去の情報を記憶しながら、最新のデータを処理できるようになります。つまり、時系列の依存関係を学習できます。以下では、RNNの中でも、長期の依存関係をうまく学習できるように専用の記憶部を備えたLong short-term memory(LSTM)を使って、自然言語処理を行います。
BERT
2018 年、自然言語処理分野においてブレイクスルーを起こしたBERT[1]について紹介します。BERT はGoogle が2018 年10 月に発表した自然言語処理タスクのための事前学習モデルです。BERT は現在、Google の検索エンジンにも使われています。BERT が特に優れている点を紹介していきます。
様々なタスクにモデルを流用できる。
BERTはFine-tuning(一部パラメータを再学習) を行うだけで、様々なタスクを高精度に行うことができます。元論文[1]では、11種類の自然言語処理タスクで論文発表時点での最高精度を達成しました。
文章の前後関係を学習している。
文章の前後関係を学習し、文脈を理解することができるモデルだと言われています。Google が実際に示している具体例[2] を紹介します。下図は『brazil traveler to usa need a visa』(ブラジル人がアメリカに行くときにビザが必要か)と検索したときの検索結果を示しています。
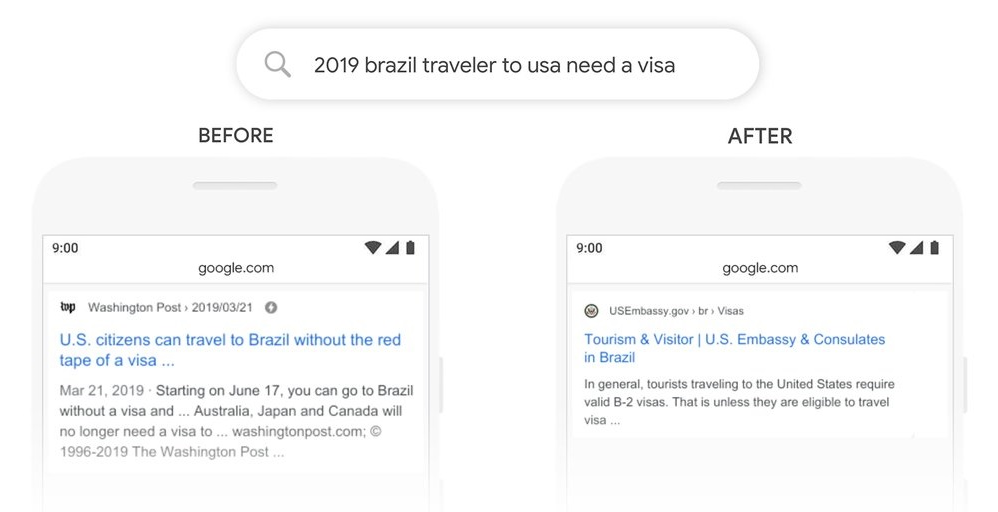
BERT導入前後のGoogle検索の比較
DistilBERT
BERTの欠点を挙げるとすれば、モデルが大規模であることです。BERTを動かすためには、12 ~ 16 GBのRAMを備えたGPUが必要になります。そこで、BERTの性能をある程度維持しつつ、パラメータの削減、高速化を実現したDistilBERT[3]というものがあります。DistilBERTはBERT-baseの性能を97%程の性能で、パラメータが40%少なく、60%高速に動作するモデルです。また、バンダイナムコ研究所がWikipedia日本語版全文を学習したDistilBERTモデルを公開しています[4]。以下では、このDistilBERTモデルを使って、自然言語処理を行います。
分類
LSTMを使って与えられた文章に対してラベルを予測する分類タスクを行います。ここでは、モデルの予測結果を混同行列(Confusion Matrix)で示します。混同行列とは、「実際の分類」と「予測した分類」を軸にしてモデルの分類結果をまとめたものです。横軸を「予測した分類」、縦軸を「実際の分類」としています。
Sentiment140[7]
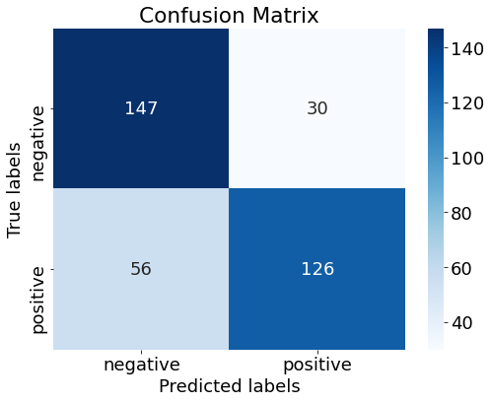
Sentiment140のデータセットはTwitterの感情分析のために作られたデータセットで、ツイートに対して感情のラベル(positive, neutral, negative)がつけられたデータです。今回、ラベルはpositiveとnegativeだけを対象とし、Sentiment140の訓練データ160万件のうち1万件を使ってLSTMを学習させ、テストデータ359件に対して推測を行いました。正答率は76[%]でした。ある程度判断ができていることが分かります。
livedoorニュースコーパス[8]
livedoorニュースコーパスは、9つの分野のニュース記事を分野毎にまとめたデータセットです。ニュース記事本文からその記事の分野を予測するタスクを行います。
3分類
「独女通信(= 0)」「ITライフハック(= 1)」「家電チャンネル(= 2)」の3分野の記事を一部(285件)取り出してLSTMの学習を行いました。学習に使っていないデータ(2317件)に対して推測した結果が以下になります。正答率は92[%]でした。学習に使用したデータは全体の一部だったのにも関わらず、正確に判断ができています。
9分類
「独女通信(= 0)」「ITライフハック(= 1)」「家電チャンネル(= 2)」「livedoor HOMME(= 3)」「MOVIE ENTER(= 4)」「Peachy(= 5)」「S-MAX(= 6)」「Sports Watch(= 7)」「トピックニュース(= 8)」の9分野の記事を一部(3200件)取り出してLSTMで学習を行いました。また、DistilBERTを用いてFine-Tuningを行いました。
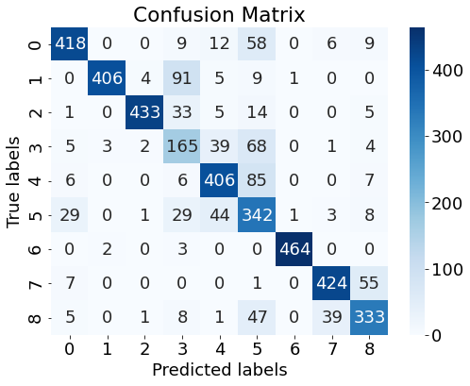
LSTM
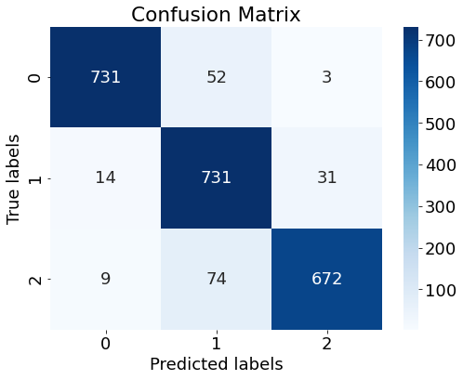
学習を行ったLSTMを用いて、学習に使っていないデータ(4163件)に対して推測した結果が以下になります。正答率は81.4[%]でした。ある程度判断ができていることが分かります。
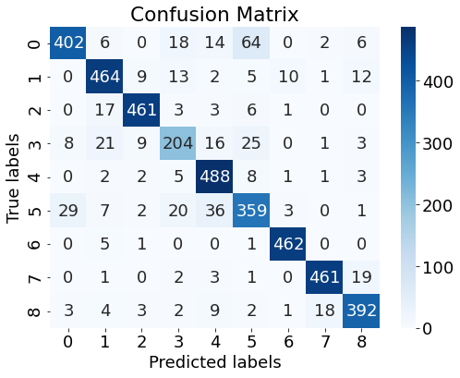
DistilBERT
Fine-Tuningを行ったDistilBERTを用いて、学習に使っていないデータ(4163件)に対して推測した結果が以下になります。正答率は88.7[%]でした。分類が9つあるのにも関わらず、約9割も正しい判断ができています。
文章生成
LSTMを使って文章生成タスクを行います。LSTMに文章や単語を与えたときに次に出現する単語を予測させるタスクを続けて行わせることで文章生成ができます。学習する文章には青空文庫[9]が提供している著作権切れの小説を使います。学習がうまくいけば、学習に使った小説に出てくるような文章を生成するモデルが完成します。
芥川龍之介「羅生門」
芥川龍之介の「羅生門」を学習させ、150単語生成させました。「ある日の」を最初の入力として与えました。文章の意味としては、よく分からないものになっていますが、言葉の表現は作品に近いものになっていることが確認できます。
ある日の暮方をしない事を、積極と共に知らなかったばかりである。洛中が欲しいほど、意識は、もう鼻と一つにふりこめられてしまうばかりである。そうして、その死骸の上へ飛び上ったの寒さである。この男のほかに誰か。」下人は、すばやくまで眺めていた死骸の首意味とか饑饉とか云うためには、それが円満分かにして、門の着物をどうにかしようと思うていた。旧記しまいにはない。旧記きっと、今時分も大目に見た。檜しまいには、通りかかったのをしない事は、何度はいって来た。「成程な梯子を、ここに
江戸川乱歩「赤い部屋」
江戸川乱歩の「赤い部屋」を学習させ、150単語生成させました。「異常な興奮」を最初の入力として与えました。こちらも文章の意味は分からないのですが、部分的に見てみると、"非常に珍らしいことです。"など文法は正しいものが生成されていることが確認できます。
異常な興奮を求めようものですし誰一人の人間のでしょうが、非常に珍らしいことです。彼は幾分あのピストルは、頃ですが……、これはないか。私は怪我をかけられた。彼女がさも快活へ潜ったのです。私の心持も夢幻的な空気は、この世し疑わしかった次第な声が、私の心持も海へ入る足寄ったものと思うと、これは又十日余りの私の外の現れ警察の人達も、皆オオ、考えられたことがあるとすれば限りもいうものな少しも悔悟なぞして異常なからくり仕掛けの強情さを私達の目に止りけは、
参考文献
[2]Pandu Nayak, ”Understanding searches better than ever before”, Oct 25, 2019.
[4]バンダイナムコ研究所, "Japanese DistilBERT Pretrained Model"
[5] 斎藤康毅 (2018) 「ゼロから作るDeep Learning 2 ー自然言語処理編」オライリー・ジャパン
[6] 麻生英樹、安田宗樹、前田新一、岡野原大輔、岡谷貴之、久保陽太郎、ボレガラ ダヌシカ (2015)「深層学習 -Deep Learning-」近代科学社
関連製品
弊社では、お客様のご要望に応じたAI活用システムの提案、作成を行っております。まずはお気軽にご相談ください。
